LAN 이나 WiFi 가 없는 보드에서 개발하기엔 불편한 부분이 많다 . 가장 불편한 부분은 수정하여 빌드한 바이너리 파일을 보드에 올려 테스트 할 떄마다 전체 커널 이미지를 다시 올려야하는 수고스러움 이다. 이때 유용하게 사용할 수 있는 방법이 USB Ethernet gadget 을 연결하여 NFS 등을 사용하는 것이다 . USB Ethernet Gadget 커널 설정 방법 Kernel menuconfig 의 Device Drivers > USB support > USB Gadget Support 에서 Ethernet Gadget (with CDC Ethernet support) 를 선택한다 . RNDIS support 도 선택해야 한다 . 특정 프로세서에서는 kernel config 이외에 다른 설정이나 소스 수정이 필요한 경우도 있다 . Allwinner 의 A20 이나 A64 등의 경우 usb gadget 커널 드라이버 소스에서 is_udc_enable=1 을 해주는 등의 소스 수정도 필요하다 . Sunxi_udc.c static u8 is_udc_enable = 1; 커널 빌드 후 이미지를 디바이스에 올린 다음 부팅한다 . 부팅 후 ifconfig 를 사용하여 usb0 의 ip 를 설정할 수 있다 . 디바이스를 windows PC 와 USB 로 연결하면 , 디바이스 드라이버를 설치하라고 나오는 경우 커널 소스의 Documents/USB/linux.inf 를 설치한다 . USB Serial Port 라고 인식하는 경우 , 장치 관리자에서 드라이버 업데이트를 선택하여 수동으로 위 linux.inf 드라이버를 설치한다 . 드라이버는 서명이 안되어 있어 , 드라이버 인증을 사용하지 않는 모드로 부팅하여 사용하던지 , 관리자 모드의 windows powershell 에서 아래 명령어를 사용하고 리부팅 후 설치해야 한다 . bcdedit.exe -...
리눅스에서 SD 카드를 포맷할 때 아래와 같이 "Device or resource busy"에러를 출력하며 포맷이 되지 않는 경우가 있다. mkfs.fat: unable to open /dev/mmcblk0p1: Device or resource busy 해결법을 찾아보았다. 이 문제의 원인은 1. 파티션 dev path 가 맞지 않거나, 2. umount가 완전히 이루어 지지 않았거나, 3. mbr파티션에 문제가 있어 발생한다고 한다. 파티션에 문제가 있는 경우 fdisk를 사용하면 문제를 해결할 수 있다. umount에 문제가 있는 경우, umount할 때 -l 옵션이 사용되는 경우 umount 명령이 끝나도 커널 내부에서 리소스가 계속 사용될 가능성이 있다고 한다. # umount -l /mnt/mmc umount2("/mnt/mmc",MNT_DETACH); 이런 경우 일정 시간 후 다시 시도하면 에러 없이 포맷이 되는 경우가 있다. 또, umount 가 되지 않을 때 "lsof" , "fuser" 명령어를 사용하여 어떤 프로세스가 mmc를 사용하고 있는지도 확인 가능하다. * lsof에서 사용 내역이 없다고 나와도, fuser에서 나올수 있다. lsof, fuser 명령에서도 mmc를 사용하는 프로세스가 없는 경우에도 "Device or resource busy"에러가 발생할 경우, umount에 -lf 옵션을 두어 강제로 언마운트 후 SD 카드를 포맷하면 "Device or resource busy"에러가 나타나지 않을 확률이 높아진다. # umount -lf /mnt/mmc umount2("/mnt/mmc",MNT_DETACH | MNT_FORCE); * fat32에서는 "-f","...
파티클 필터(particle filter)는 칼만 필터(kalman filter) 와 마찬가지로 노이즈가 있는 환경에서 측정된 데이터를 필터를 사용해 실제 위치를 추정하는 도구다. 파티클 필터(particle filter)는 보통 가우시안 분포가 아닌 측정 데이터를 다루기 위해 사용된다고 한다. 물론 가우시안 분포의 데이터에서 사용하지 말라는 건 아니다. 본 포스트에서는 파티클 필터(particle filter)의 어려운 수학적인 내용은 제하고, 쉽게 예를 들며 필터의 동작원리에 대해 알아보았다. 파티클 필터(particle filter)에 대해 검색해 보면 아래와 같은 그림을 많이 보게 된다. 아래 그림은 파티클 필터의 estimation cycle을 도식화한 것이다. <’Real-Time Tracking of Multiple Moving Objects Using Particle Filters and Probabilistic Data Association’ original scientific paper 中> 위 그림의 검은색 원들은 particle을 의미한다. 이 particle에는 보통 위치 데이터와 weight가 포함된다. 검은색 원이 큰 것이 있고 작은 것이 있는 이유는 weight가 크고 작음을 의마한다. typedef struct _particle_t { int x; int y; float weight; }particle_t; 노이즈가 있는 환경에서 레이저 센서나 레이더등을 이용하여 물체의 위치를 측정할 때를 가정해 순서대로 이 필터가 동작하는 과정에 대해 알아 보겠다. (순서는 위 그림과 조금 다르다) 1. 초기 상태 측정 범위안에 랜덤 혹은 일정한 간경으로 particle을 뿌려 놓는다. 이 떄 particle...
Constant False Alarm Rate (CFAR)은 기본적으로 테스트하고자 하는 위치의 cell과 주변 cell의 관계를 보고 테스트 cell이 Target 인지 아닌지를 구분하는 알고리즘이다. 주변 cell과의 관계를 어떤 방식으로 비교하는가에 따라 여러가지 알고리즘이 존재한다. CA-CFAR, GO-CFAR, SO-CFAR, OS-CFAR, VI-CFAR, OSVI-CFAR등이 있다. 이 많은 알고리즘 중 간단하고 기본적인 CA-CFAR과 OS-CFAR에 대해 알아보자. CA-CFAR (Cell Average CFAR) CA-CFAR의 원리는 위 그림과 같다. 좌우의 Reference Cell의 평균에 Scale Factor T를 곱하고, ADT (Average Decision Threshold)를 합하여 CUT가 타겟인지 아닌지를 구분한다. ADT는 신호의 white noise를 고려하기 위해 더해준다. Scale Factor T와 ADT는 아래와 같은 공식으로 사용할 수 있다. 사용하려는 시스템에 따라 공식은 달라질 수도 있다. Pfa는 False Alarm 발생 확률을 나타내고, M과N는각 좌우의 Reference Cell의 개수를 나타낸다. OS-CFAR (Order Static CFAR) OS-CFAR의 원리는 위 그림과 같다. 좌우의 reference cell중 K번째 큰 값의 cell을 Reference Cell의 대표 값으로 정해 CUT가 타겟인지 아닌지를 구분한다. 보통 전제 reference cell의 크기 순에서 (3*N)/4 번째 cell이 성능이 좋다고 알려져 있다. CFAR 사용 예 아래 사진은 위 두 cfar을 사용한 예다. 파란색은 신호이며, 붉은 색은 char을 사용해 만든 threshold이다. 이 threshold보다 큰 값의 신호가 있는 위치에 실제 Tar...
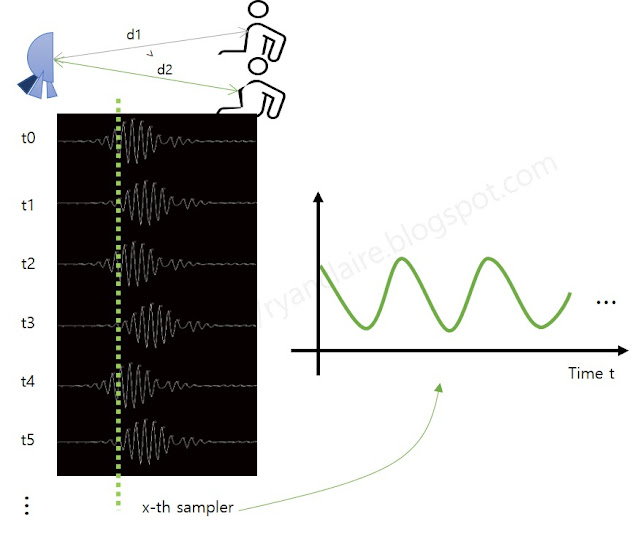
본 글은 UWB Radar를 사용하여 사람의 호흡수를 측정하는 원리에 대해 싣고 있다. 전에 블로그에서 UWB Radar를 사용하여 거리를 측정하는 원리 에 대한 글을 올린 적이 있다. 이번에는 호흡을 측정하는 원리에 대해 알아보겠다. 기본적으로 레이더는 레이더와 레이더 측정범위내의 사물과의 거리를 측정하는 도구이다. 그리고, 사람은 배 또는 가슴을 움직이며 숨을 쉰다. 간단히 이 두가지를 이용하여 UWB레이더로 사람의 호흡을 측정할 수 있다. 사람이 호흡할 때 마다 변하는 가슴/배의 위치를 UWB레이더로 측정하여 호흡수를 산출해 낼 수 있다. 아래 그림은 UWB Radar를 사용해 사람의 호흡수를 측정하는 원리를 도식화한 것이다. UWB Radar를 사용하여 일정 시간 t동안 호흡하는 사람의 거리 데이터를 측정하면 위 그림 왼쪽처럼 위치의 변화가 측정된다. 이는 호흡할 때 움직이는 가슴/배의 위치를 포착하기 때문이다. 이 측정된 데이터에서 가슴/배 위치의 sample 데이터를 시간 순서로 배열하면 위 그림의 오른쪽처럼 그 크기가 변하는 것을 볼 수 있으며, 이는 측정된 사람의 호흡과 일치하는 것을 알 수 있다. 이 시간순으로 배열된 데이터를 사용하여 호흡수를 산출한다. 호흡수는 시간과 파형의 간격을 이용하여 산출할 수 있다. 예를 들어 아래처럼 2회 호흡에 200ms가 걸렸다면, 1분당 호흡수는 2*1000ms/200ms = 10회로 계산할 수 있다. 그리고, FFT를 사용하여 파형의 주파수를 분석을 통해 호흡수 산출도 가능하다. 호흡 파형에서 크기가 가장 큰 주파수가 0.167hz이면, 1분당 호흡수는 0.167hz*60sec = 10.02회로 계산할 수 있다. 관련 글: UWB Radar 거리 측정 원리 uwb radar 호흡수 측정 방법 ...








댓글
댓글 쓰기